What I’ve been playing with
Oct. 24th, 2010 04:47 pm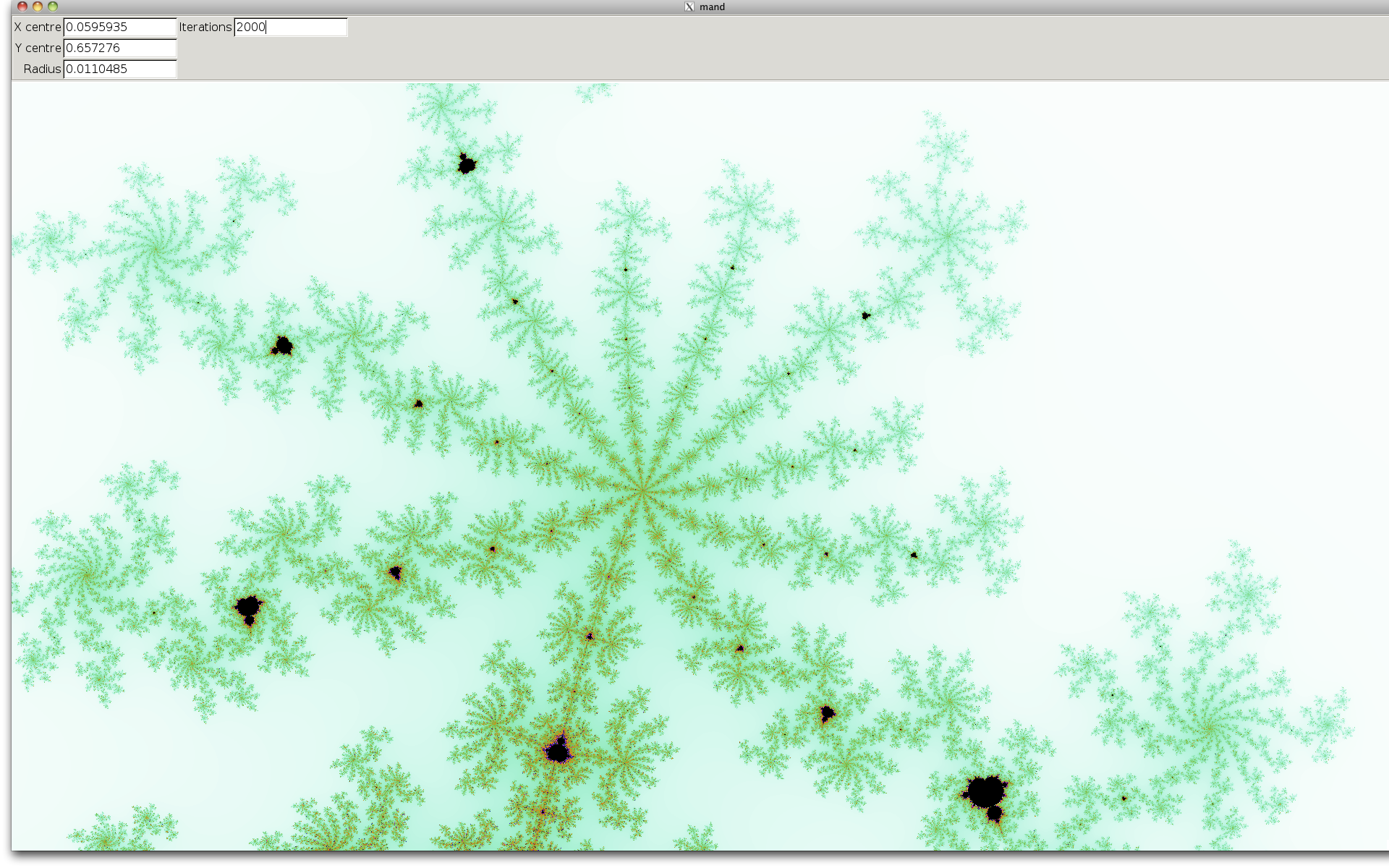
(Click on the image for a full-size version.)
I first encountered this stuff in my teens, via computer magazines, a friend with shared enthusiasms, and James Gleick’s book Chaos. My first attempt was in BASIC on a Sinclair QL, and very slow; it was nowhere near finished even the following morning. I had a lot of fun creating a faster version in 68K assembler using fixed point arithmetic (16 integer bits, rather more than required, and 32 fractional bits, as I recall).
Since Benoit Mandelbrot’s recent death there’s been a lot of references to it online, and that inspired me to revisit it this weekend. The visible results are above, and my program (still very much a work in progress!) can be retrieved using:
git clone http://www.greenend.org.uk/rjk/git/mand
Read the README. You will need a Linux or OS X system with the GTK+ libraries installed.
(no subject)
Date: 2010-10-24 03:49 pm (UTC)(no subject)
Date: 2010-10-24 04:29 pm (UTC)Looking around it seems that most people have concentrated more on interesting renderings recently rather than simple deep exploration, there's some nice examples of plotting the orbits of large numbers of random points (http://erleuchtet.org/2010/07/ridiculously-large-buddhabrot.html), and just how much that can be accelerated with a modern GPU.
(no subject)
Date: 2010-10-24 04:51 pm (UTC)...OK, I got bored and dumped the assembler, it saves an instruction overall, and you save another instruction in the main loop by reordering the test to have the iterations after the >4 test.
Depending on how the instructions pack in the pipeline, that could be 10% speedup.
Originally GCC 4.5.1 on a Core 2 produced:
After the tweaks above (and compiling with -march=native, which just changed the addl $1,%eax to an incl %eax), it produced:
(no subject)
Date: 2010-10-24 05:36 pm (UTC)(no subject)
Date: 2010-10-25 07:34 am (UTC)Like several others, your post just caused me to remember playing around with Mandelbrot sets, and how it was a problem that really showed the benefits of inner loop optimisation. (I don't know enough SSE to know if the latter is the best solution).
(no subject)
Date: 2010-10-25 08:18 am (UTC)(no subject)
Date: 2010-10-25 10:44 am (UTC)They claim 5.2 billion iterations (of zn+1 = zn2 + c) per second on a modern 3.2GHz quad core CPU, which seems rather impressive.
(no subject)
Date: 2010-10-24 08:25 pm (UTC)(no subject)
Date: 2010-10-24 11:28 pm (UTC)Then there was: http://www.ioccc.org/years.html#1992_imc
We had monochrome sparcs back in those days. It needs big-endian architecture to output a valid .ras file, though the fix is not that difficult.
(no subject)
Date: 2010-10-25 09:26 am (UTC)http://www.biff.org.uk/dave/95.html
(no subject)
Date: 2010-10-25 10:32 am (UTC)only wrapped continuously around the border of the M-set.
(no subject)
Date: 2010-10-27 07:21 pm (UTC)One of these perhaps?
(no subject)
Date: 2010-10-27 08:59 pm (UTC)